Large Language Models (LLMs) can now write code, draft memos, summarize earnings calls, and automate complex tasks with ease. But ask them to extract 30-line items from a scanned utility bill, and all best are off.
A 2024 survey of multimodal models documents persistent hallucinations, a particular problem when text is faint, skewed, or arranged in nested tables. This happens because most scanned PDFs must first go through optical character recognition (OCR) to be converted into machine-readable text. When the OCR layer fails to accurately extract characters due to noise, poor resolution, or inconsistent formatting, it introduces gaps, distortions, or ambiguities in the input.
LLMs aren’t inherently designed to validate or correct these OCR errors. Instead, when faced with broken or incomplete data, they rely on pattern completion generating what seems contextually appropriate based on training, even if it wasn’t in the original document. This leads to confident but fabricated outputs: the “$123.45” you expected might morph into “$12,345” halfway through the pipeline. The model isn’t intentionally lying it’s guessing to fill in the blanks, and doing so with dangerous confidence.
Why Is PDF Extraction So Thorny?
Most PDFs aren’t actual text files, they’re images in disguise. Scanned contracts, invoices, tax documents, and intake forms require optical character recognition (OCR) to convert pixels into machine-readable characters.
But even state-of-the-art engines can still struggle on low-resolution scans and non-linear text flow. When this broken input is fed into an LLM, things spiral: the model hallucinates plausible-sounding but incorrect values, due to missing or corrupted context.
These aren’t minor typos. They’re fabricated financial figures, a critical failure for teams in finance, legal, healthcare, and operations who rely on PDF data extraction for regulatory reporting, billing, and audits.
That’s why fixing downstream errors starts at the input layer and that’s exactly what Unity AI OCR was designed for.
Unity AI OCR: Clean Inputs. Confident Automation.
Unity AI OCR directly addresses the root cause of LLM output errors: bad or ambiguous document data. It’s not just another OCR tool, it’s a domain-trained document intelligence engine, purpose-built for enterprise use cases.
Here’s how Unity AI OCR works:
- Domain-Trained Models:
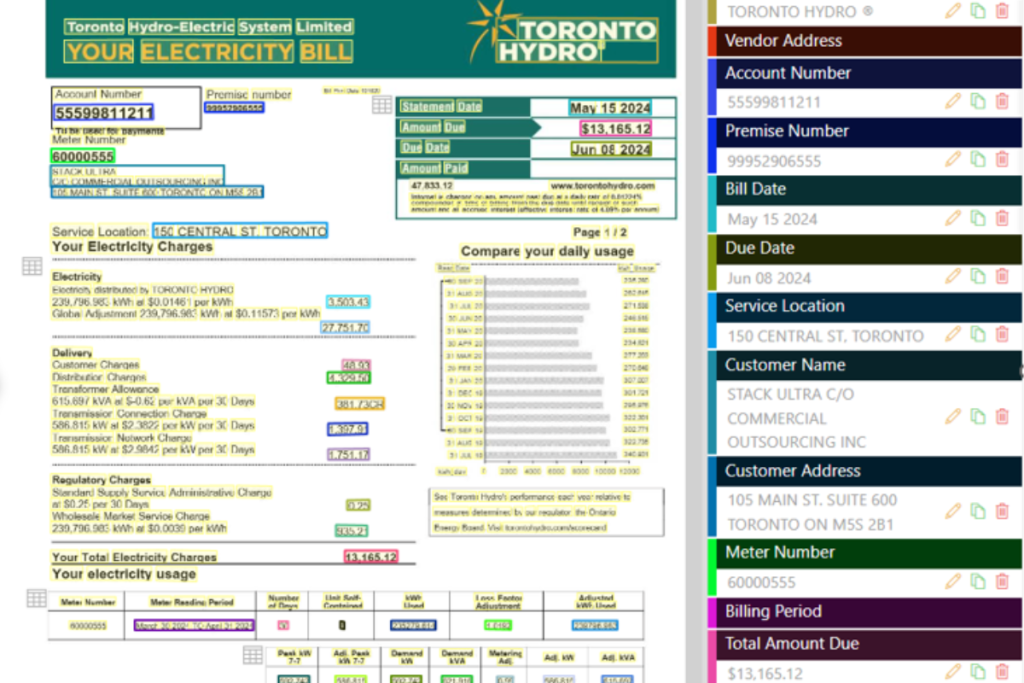
Whether it’s a utility bill, government form, invoice, or legal PDF, Unity’s models leverage a deep knowledge base of annotated documents to map out layout, field relationships, and noise tolerance. - Self-learning Capabilities:
An intuitive mapping and annotation process allows Unity AI OCR to self-learn adjustments for future data extraction, ensuring key values like invoice totals, meter numbers, tariff adjustments, and account IDs are mapped to their correct labels, regardless of format or quality. - Smart Data Tables:
Once extracted and validated, the data flows directly into Unity’s Smart Data Tables, enabling workflows like invoice reconciliation, financial audits, and compliance reporting with zero output errors and 100% traceability. The clean data can also be exported via CSV or fed into other downstream processes via API.
Why This Matters to Your Business?
LLMs are powerful but they’re only as trustworthy as the data they receive. When your workflows involve scanned documents, PDFs, or image-based forms, the OCR layer becomes your first point of failure.
If your input is wrong, your AI guesses. That’s not just a technical inconvenience, it’s a business liability. The consequences?
- Failed compliance audits
- Miscalculated tax return
- An incorrect customer invoice
- A flawed decision based on hallucinated numbers
If your organization relies on document automation and expects LLMs to handle critical data, you need to start with clean, structured, and trusted OCR output.
Unity AI OCR Fixes the Source, Not Just the Symptoms
With Unity AI OCR, you get:
- Accurate PDF data extraction
- Audit-ready, hallucination-free automation
- Scalable, compliant document workflows from the ground up
Because automation without trust is just guesswork.
Learn more about Unity AI OCR and how it powers Unity’s Smart Data